MEMS3 Firmware Correlation –
Identifying Tables & Scalars in All Firmware Versions
Download
Link: https://andrewrevill.co.uk/Downloads/MEMSTools.zip
MEMS Mapper can now identify known
tables and scalars in almost all firmwares with a very high degree of accuracy.
There are many different firmware
application versions for the MEMS3 ECU, covering numerous iterations of the
MPI, VVC, automatic, turbo, Rover 75 and Freelander flavours of the ECU, as
well as several variants of the Land Rover Td5 ECU. Since I first wrote MEMS3
Mapper, it has had the ability to identify known tables and scalars in
previously unseen firmware versions. This is achieved by comparing the data in
tables with all tables seen previously in other firmwares and looking for
similarities. For large tables mapped in high resolution, such as ignition
timing and fuelling / VE tables, this has generally worked well. However, a lot
of the smaller tables often only contain a few data points, and in some maps
whole features are disabled in which case the corresponding tables may reduced
to a single point with a zero value, which doesn’t provide enough information
for a reliable identification. For scalars, the matching algorithm relied on
spotting similar patterns of numbers either side of the scalar in question.
This has also generally worked quite well, but was not infallible. So, in some
cases, in unkeen firmwares, the application has misidentified tables and
scalars.
Recently I was fortunate enough to be
given copies of a full set of the Rover T4 system CDs. Initially I didn’t think
there was actually a lot I could do with them, not having a T4 system myself,
but then it occurred to me that the T4 system was capable of upgrading any
MEMS3 to the latest (at the time of issue) firmware and map for that particular
vehicle, which must mean that there was a large selection of firmware and map
files somewhere on the CDs, probably covering all of the firmware versions ever
issued to the dealer network, which in all probability meant the vast majority,
if not all, of the firmwares ever installed on production vehicles. So, I went
digging.
At first there was nothing obvious;
certainly not a nice folder containing firmware and map files that I could
recognise. But on each CD there was a large database
file ROVER.DAT and a corresponding index file ROVER.IDX. Many different
database engines over the years have used .DAT and .IDX file extensions and I
tried to open these files with numerous different drivers for all of the main
suspects, but none of them worked. So I tried doing it
the hard way and opening the database files in a binary editor and searching
for byte sequences which I knew to be in the firmware. Sadly, nothing showed
up. Then I thought, what if they’re actually held as hexadecimal-encoded text
strings in text fields? So tried searching for the hexadecimal representations
of known byte strings, and BINGO! There they were. With a bit more poking, I
realised that they were in Motorola SREC format, which was not at all
surprising as the ECUs were made by Motorola.
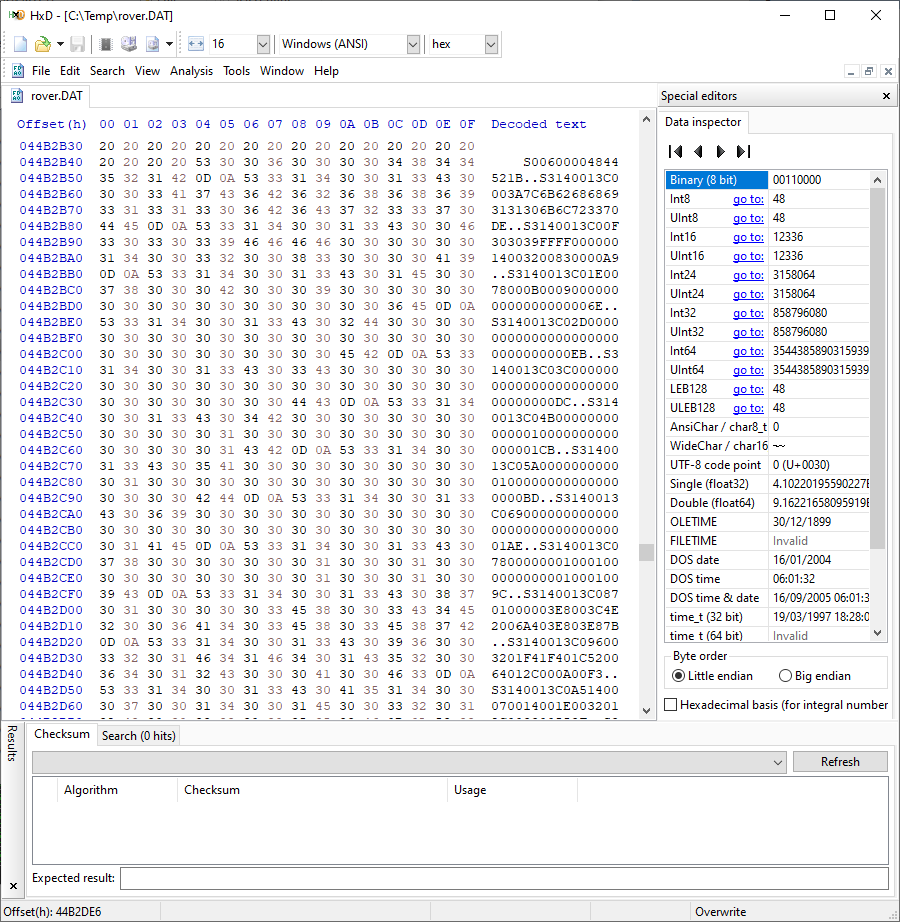
Finding all of the maps and firmwares in
SREC format made them really easy to parse out and extract. As I couldn’t read
the databases properly, I had no identification information for each file, but
luckily the firmware and map IDs, and the firmware ID for each map, are encoded
into the headers of the files. I therefore was able to extract a full set of
firmware and a full set of maps, and pair them up based on their IDs to produce
full ECU images. Unfortunately I still wasn’t able to
identify exactly what vehicle each pair was associated with, but there was
still a lot I was able to do with these files. The complete library of all of
the files recovered is online here: MapFirmwareLibrary/From%20TestBook%20T4%20CDs/
with some 166 files in total, covering 40 different petrol firmware versions
and 13 Td5 diesel firmware versions.
Armed with every firmware version ever
issued, I was in a position try to do a much better job of correlating all of
the tables and scalars across all firmware versions, making the problematic
in-application identification algorithm pretty much obsolete.
I ran every single firmware version
through a disassembler to produce a plain-text, assembly language listing (the
MEMS Mapper application already used these files in the same format for
automated reverse-engineering when installing customised firmware patches
etc.).
My first attempt was then to try to
correlate all of the tables by hand. I made some changes to MEMS Mapper to
allow me to:
1.
On any table or
scalar, right click and select “Search Firmware” to see the point(s) in the
assembly language listing where the table or scalar was referenced.
2.
On any table or
scalar, hold the mouse over the table list for a pop-up hint showing the listing
of the code which referenced it.
I then spent many, many evening hours
comparing not only the data in each table, but the code that accessed it,
trying to work out and make a judgement call what corresponded to what. It took
days of effort, but I got there in the end and was convinced that I’d done a
reasonable job. But trying to do it for the scalars filled me with dread. It
was a mammoth task for the tables, where I had a lot more data to go on and
typically 150 tables in any firmware version. There were
something like 1400 unique scalar values to trawl through, and each one was
just a single number. There was no way I was going to be able to do them all by
hand. So I set about trying to write program code to
do what I had done on the tables by hand, i.e. to compare the code accessing
tables and scalars and to identify where it was similar (not necessarily
identical, as the code did change in places over time).
I tried several different comparison
algorithms. Most of them revolved around looking for “similar” instructions at
“similar” distances from the code that accessed particular tables. I tried
weighting the scores based on the distances of the instructions from the table
reference (code further away was considered less relevant) and the distance between
matching instructions in the two firmwares (matches in corresponding positions
were considered more significant). They were all plagued by problems. The main
issue was trying to define what was “similar” in a way that caught all of the
places where tables were accessed by slightly different code, without linking
together unrelated tables just because there were similarities in the code
around them. Without being able to follow the full program flow logic (which
was almost impossible to do in an automated way) I was left with blindly
comparing code in proximity to the table access, and that had a number of
problems:
·
A lot of tables
seemed to be accessed by dedicated subroutines with the structure: Load
register d1 with the table address, load register d2 from the variable that
holds the X-axis value, load register d3 from the variable that holds the
Y-axis value (in the case of a 3D table), call the table lookup function, store
the result d1 into a variable. In other words, the code immediately surrounding
the table access was identical across many tables.
·
This meant I had to
look beyond the subroutine in which they were accessed. But following the tree
of calls was just impossibly complex, so I had to content myself with looking
at the structure of preceding and subsequent subroutines.
·
These could also be
very similar, as you often see a long run of consecutive identical table-getter
routines in the code.
·
I often found code
inserted before or after a table-getter routine between two different
firmwares, which meant the code after the getter might be identical, whereas
the code before it was unrelated. So I had to resort
to scoring the code before and after and taking the higher score.
All in all, I was able to get some very plausible matches with high scores,
but there were always some false matches mixed in. I would have been happier to
accept that it missed some matches than that it was matching together tings
that really weren’t the same, but it really wasn’t possible to define clean
cut-off point based on scores and confidence levels. Then I hit on the idea of
not using a score cut-off, but rather insisting that any matches must work both
ways. So, my reasoning was that if the highest-scoring match for firmware FA
table TA in firmware FB was TB, then if this was a genuine match it should work
the other way around and the highest-scoring match for firmware FB table TB in
firmware FA should be TA, whereas if it was spurious match then it would be
more likely to link back to say TC. On this basis I prepared some
correspondences between tables in pairs of firmwares, and then compared them to
the hand-generated correspondences before. It was all a bit disappointing.
There were a lot of differences, and when I looked at them, in lot of cases it
had found very high degrees of match in both directions between tables that
were just unrelated. It began to feel like some of the things we found when
testing ChatGPT AI at work; it always seemed to be able to give a very
plausible and convincing answer, even with very plausible and convincing
reasoning behind it, but it was probably wrong!
It was all beginning to feel a bit desperate, so I left it alone for a
few days to think.
One thing I realised was how much code I had seen that was very
similar across ECUs that were very different. For example, the Rover 75 / MG ZT
line of ECUs are in many ways a lot more distantly related to other MEMS3
applications that the other MEMS3 applications are to each other. They use a
lot of BMW-class security and have a lot of code differences. But the Rover 75
Turbo ECUs have a lot of additional turbo-related code over the Rover 75 NASP
ECUs, and large parts of this extra code were identical to code I’d seen in the
development MG ZR Turbo firmwares, where it was added in to the regular ZR ECU
instead. It seemed as though the “modular” in Modular Engine Management System
(MEMS) carried over into the software design as well as the hardware; it felt
like there was basically a master menu of different modules, and all of the
MEMS3 firmware variants were essentially made by selecting a subset of these
modules at compile time. It was almost as though you could draw up a “master
MEMS3” firmware containing everything, and then just delete the bits you didn’t
want in any given ECU. The different modules even seemed to appear in petty
much the same sequence in the code wherever they appeared together. So, I
decided to see if I could try to find the common modules, and use those to
identify tables.
This is how I went about it:
·
Convert each binary
firmware to a text listing by passing it through a disassembler.
·
Convert each
listing into a “comparable form”, line by line. This meant:
o
Stripping out
comments inserted by the disassembler.
o
Stripping out labels,
as the code modules would be compiled at different addresses in different ECUs.
o
Stripping
consecutive whitespace from the disassembled code, to ensure identical
instructions were always formatted identically (the whitespace could different
for example where corresponding addresses were 3 digits long e.g.
$FFE or 4 digits long e.g. $1002).
o
Stripping out
references to explicit scalar addresses, of the form “$NNN(a5”,
which I reduced to “$(a5”.
o
Stripping out
explicit 6-hex-digit addresses, to account for the fact that the code may be
compiled at different addresses.
o
Stripping out
addresses that looked like table addresses, so instructions of the form “move.w #$2NNN,d1” or “move.w #$3NNN,d1”.
o
Stripping out
variable addresses (valid RAM addresses of 1, 2, 3 or 4 hexadecimal digits in
several forms of instruction used to refer to RAM variables).
o
Stripping out bit
numbers for Boolean flags, as the compiler may pack different bits into bytes,
so treat them as addresses.
o
Stripping out
branch lengths. In 68000 assembly, branches to other addresses may be specified
with different size offset operands, and the compiler would use the shortest
instruction that would allow a long enough jump. If the modules were compiled
at different addresses it may be forced to use a long
branch, so all branch instruction lengths should be treated as equivalent.
o
Stripping out “null
subroutine” names. The disassembler distinguished between subroutines with
instructions, which it names in the form “sub_NNNNNN”, and subroutines which are
empty, which it names “nullsub_NNNNNN”. If a module was omitted, sometimes a
stub subroutine was called but nothing was compiled into it. From the point of
view of the calling code these two cases should be treated as identical, so I
converted “nullsub_” references into “sub_” references.
o
Stripping out
“data-defined labels”. The RTS (return from subroutine) instruction has the
hexadecimal code $4E75. Sometimes the disassembler would see this as being
string data, the characters “Nu”. Labels for subroutines that just contained a
return instruction that were pointed to in data would then be assigned in the
form “aNu”. In other cases, these would be assigned as “word_NNNNNN” where
$NNNNNN was the hexadecimal address. As this was just a quirk of the disassembler
and not a feature of the binary code, I converted “aNu” type references to
“word_NNNNNN” type references.
o
Stripping out all
constant binary data. Sometimes in the code there were blocks of bytes that the
disassembler had not managed to make sense of, and were just listed as byte
arrays. There were usually tables of records embedded inline in the code and
often contained addresses, meaning that they were different between firmwares,
so I replaced all constant byte blocks with a single DC marker.
Doing all of that meant that for each
firmware, I had a file which kept most of the “shape”, structure and detail of
the original code but in a form that was independent of the address at which it
had been compiled, and which was independent of other choices which the
compiler was free to make that were not explicitly features of the source code.
An example of some code converted to “comparable form” is shown below:
dc
bsr.w sub_
btst #,($).w
beq.s locret_
bsr.w sub_
rts
clr.w d1
move.b ($).w,d1
cmpi.w #2,d1
bcc.s locret_
movea.l off_(pc,d1.w*4),a0
nop
jmp (a0)
rts
dc
bsr.w sub_
bsr.w sub_
move.b #1,($).w
bra loc_
rts
bsr.w sub_
rts
rts
lea ($FFFFF230).w,a0
move.w #0,d0
move.w $(a5),d2
subq.w #1,d2
move.w #0,d1
bra loc_
addi.w #1,d1
cmp.w d2,d1
bgt.s loc_
move.w $(a5,d1.w*2),d3
move.w d0,d4
add.w d3,d4
move.w d4,(a0,d1.w*2)
bra loc_
move.w #0,d4
addi.w #$3F,d4
move.w d4,(a0,d1.w*2)
move.w #$3D,($FFFFF20A).w
move.w #$500,($FFFFF20C).w
bclr #,($FFFFF210).w
rts
move.w ($).w,d0
sub.w ($).w,d0
ext.l d0
divs.w #$64,d0
bpl.s loc_
addi.w #$48,d0
As you can see can see, the text still
retains a lot of the original details which means that it is good for matching
reliably, but has no information about the address at which it was compiled.
Stripping out all of the address information has certainly not left featureless
code that could match anything. Numeric constants (such as the $3F shown above)
which were not treated as addresses were retained, as were addresses outside of
the RAM and EEPROM address ranges (such as the $FFFFF20A register address shown
above). Register numbers were also retained.
The algorithm then proceeded as follows:
·
Look for the
longest runs of identical matching instructions (at any address, in comparable
form as above) in the two firmwares.
·
Cut out the
assembly source code for these blocks and add to two lists of matched
instructions (the instructions before and after these blocks remain in the
original source lists following each other).
·
Repeat until the
longest matching run is less than 32 instructions (below which the matching may
not be reliable).
·
Sort both lists
based on the original source addresses in the first list (to put any procedures
broken apart back together etc.).
This would then result in two lists of
instructions which were known to correspond exactly in the two firmwares. I
just hoped that large sections of the code could be matched up this way.
I tried running this between a VVC and a
non-VVC MPI K Series firmware and the results were really surprising, and a lot
better than I could have expected:
·
In the first pass
it found a single run of over 12,000 consecutive identical instructions.
·
Subsequent passes
continued to find runs of several thousand instructions.
·
When it finished,
it had matched up:
o
33,964 out of
35,859 instructions in the VVC file, leaving 1,895 unmatched, covering 94.7%
of the code.
o
33,964 out of
34,543 instructions in the MPI file, leaving 570 unmatched, covering 98.3%
of the code.
So what it was telling me was that the VVC ECU was basically identical
to the MPI ECU, plus about 1,300 code instructions that were specific to the
VVC. The MPI code that it had not matched to code in the VVC ECU really was
just made of scraps where there were minor differences between the two. It only
contained 18 scalar references and no table references at all, meaning that
every single table used in the MPI ECU also existed in the VVC ECU and could be
correlated exactly.
Now I had a method that could reliably
identify all of the corresponding code between any given pair of firmwares, it
was easy to scan the two lists and pull out the corresponding table and scalar
references in each. For example, where I had found a run of say 3000 identical
instructions in the two firmwares (after converting to the comparable form
described above), and instruction number 1523 in each of them referred to a
table, I could be pretty much 100% sure that the two tables in the two
firmwares were exactly equivalent.
In my library of files from vehicles and
from the T4 CDs, there are 40 petrol firmware versions and 13 diesel firmware
versions. This meant there were 40*39=1560 possible pairs of petrol firmwares
to compare and 13*12=156 possible pairs of diesel firmwares to compare. It was
not possible to cut this by a factor of 2 by assuming that the comparison
operation is symmetric and so comparing firmwares FA and FB also gives us all
of the information about a comparison of FB and FA. I had to consider the
possibility that in a later firmware they may have split a table into two,
meaning that if table TA was referred to in two places in firmware FA, the
corresponding code in firmware FB may refer to two different tables TB1 and
TB2. In this case, both TB1 and TB2 would be listed as correlating to TA as all
of the code referencing TB1 or TB2 would correlate to code referencing TA, but
TA would not correlate to either TB1 or TB2 as the correlation information was
inconsistent.
That made a total of 1726 pairs of
firmwares to compare; each of which needed every possible run length of
instructions at every possible combination of base addresses comparing, which
was a pretty enormous number-crunching job. I optimised the code as far as I
possibly could (lock-free thread-safe code that I could run in parallel, using
integer indices into a hash table of strings which meant I was comparing
integers instead of strings etc.) and ran it on 12 threads in parallel on a
6-core computer. It still ran the machine at 100% CPU usage fat out for a total
of more than 13 hours (but this didn’t matter as it was a one-off job). The
results were, for each possible pair of firmwares:
·
A CSV file listing
all of the correlated instruction addresses.
·
A CSV file listing
all of the correlated table addresses.
·
A CSV file listing
all of the corelated scalar addresses.
·
A CSV file listing
all of the correlated RAM variable addresses.
·
A text file listing
all of the instructions in the first firmware that did not correlate with
instructions in the second firmware.
I then added code at the end which
consolidated all of the above, grouping together e.g.
all tables which correlated to each other in different firmwares. I was quite
tight on my definition of a common “class” of tables. I listed all tables in
all firmwares. For each one that was not already assigned to a class, I looped
over the other firmwares looking what it correlated to. These correlated tables
were only added into a class with the table in question if they in tun
correlated back to every table already in the group in the corresponding
firmware. This meant that I grouped together tables in group of firmwares only
where they all correlated directly with every other table in the group to be
safe. This produced (in each case, one for petrol, one for diesel – click the
links to see the files produced):
·
A file listing the
correlated code addresses across all firmwares. Petrol
Diesel
·
A file listing the
correlated table addresses across all firmwares. Petrol
Diesel
·
A file listing the
correlated scalar addresses across all firmwares. Petrol
Diesel
·
A file listing the
correlated RAM variable addresses across all firmwares. Petrol
Diesel
Some brief notes on the above files:
·
Each file has a
header record with the firmware versions across the top.
·
Each file has a
“Class” column down the left, where the code has assigned consistent names to
each class based on which firmwares they appear in.
·
Each file has a
“Count” column which identifies how many firmwares each class was identified
in.
·
The tables files
have additional header records. The ECU places an index of pointers to the
table data locations at the end of the map. In the code, the tables are
referred to by their fixes addresses within the index (which is the address of
a pointer to the table data, not the actual address of the table data itself,
as this may vary from one map to another depending on the sizes of other
tables). When I first started developing MEMS Mapper I didn’t fully understand
this structure in the code and so I referred to the tables based on their
position in the index, table 0 being the first (and not usually a normal table
in petrol ECUs where it is only axis data, with the body data in RAM), then
table 1, tables 2 etc. In hindsight it would have been better and more
consistent to have identified the tables by their index pointer addresses, but
the definition I have used is still valid and workable. To convert an index
address to a table number, we need to know where the table index starts, i.e. the address of the pointer to table 0. In petrol ECUs
this is easy to find, as the special RAM table 0 has its own lookup function.
Find this, and the address it uses is the address of the index entry for table
0, with the rest following as consecutive two-byte offsets. In diesel ECUs,
every table is “normal” and every table appears to be referenced in code, so
instead I assume that the lowest address of any table accessed in the code is
table 0.
It's clear from those files that there’s
a huge degree of commonality across all of the MEMS3 firmwares. For example,
there appear from these files to be 250 unique tables used across the whole
petrol MEMS3 range (it’s actually slightly fewer in reality, see below). Of
those, 123 are shared across all 40 firmware versions and so appear in all
petrol firmwares. With any given firmware using about 150 tables, that’s about
80% of the tables common across the whole range. A further 27 tables appear in
30 or more firmwares. You can clearly see where blocks of tables, scalars and
firmwares appear in whole sets of related firmwares for VVC, turbo or automatic
ECUs. This clearly validates the original assumptions about the modular
structure of the various firmwares.
One interesting observation is that he
“Base” and “Turbo” modules clearly both contain a definition of the ignition
timing base map. So non-turbo ECUs all have one ignition timing base map, while
turbo ECUs end up with two copies. The copy corresponding to the “Base” module
still exists in turbo ECUs but isn’t referenced anywhere in the code as the one
from the “Turbo” module appears to override it. The “Base” version of the
ignition timing map then often contains a full but completely different and
inappropriate ignition timing map, inherited from the “Base” module (the
structures of the two tables are absolutely identical, it’s just the numbers
that differ). As an aside, this sort of thing is seen in other places in the
ECU too. When you’re working on the code, you soon realise that the base ECU design
supports up to 8 cylinder engines. The number of
cylinders is set at compile time, so you see a lot of loops from 1 to 4 looping
over the different cylinders, but the data structures behind them are 8 entries
long. Rover only ever used the MEMS3 in production on 4
cylinder engines, but they clearly experimented with it with the KV6
engine. For example, there is an array in scalars that gives the engine angles
at which each cylinder reaches TDC. This is 8 entries long, the first 4 values
are always correct for a 4 cylinder engine, but
entries 5 and 6 (not referenced in code that only loops over the first 4
entries) contain the values which would be correct on a KV6 engine. The last
two entries are unused and contain 0; Rover never did put a KV8 into production.
To validate the approach further, I then
compared the petrol tables file with the one I had made by hand previously.
This was the point at which previous algorithms had been found wanting. In this
case, the agreement was very good indeed, with a few exceptions:
·
There were a few
cases where the code handling a table had changed significantly, but by eye I
could see that the overall definition of the table was the same. In these cases the automated algorithm had not necessarily put them
together as one class where I had in my file.
·
There were a few
cases where I’d clearly got it wrong when doing it by hand.
·
There are a few
tables in some firmwares which just seem to be redundant and are never
referenced in code. By hand, I’d matched some of these up based on the data
they contained. The automated algorithm had nothing to go on as there were no
code references, so had left them unmatched. To be fair, if they’re not
referenced in the code they’re not really “the same” or “different” when
classifying them based on the code that uses them so I could happily accept
this as being correct.
I only found one single instance where
the automated algorithm had paired tables together where I believed them to be
different, and that proved to be very interesting. Both the final
code-alignment algorithm and the latest version of my proximity-scoring
algorithm both insisted that these two tables were equivalent:
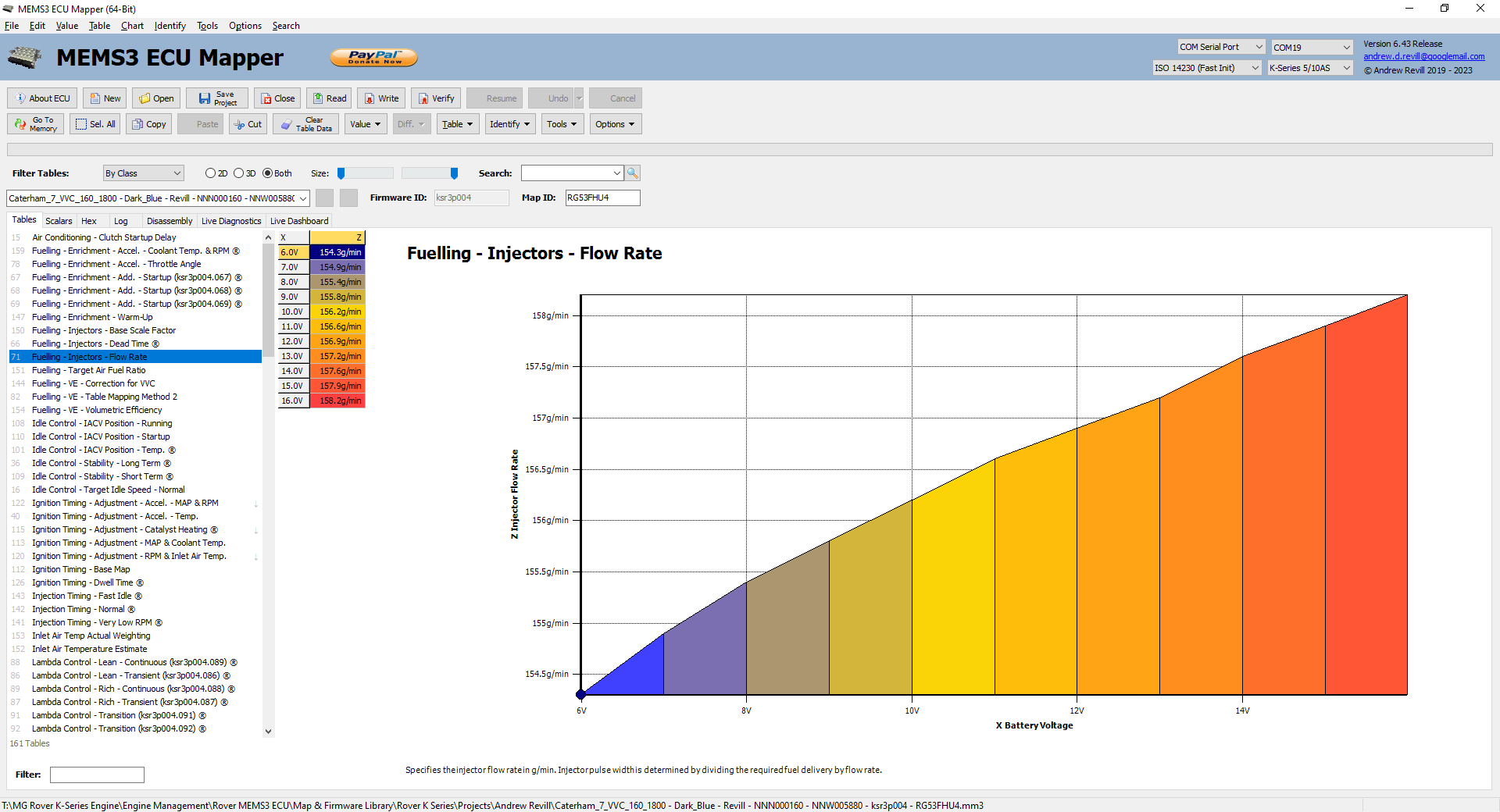
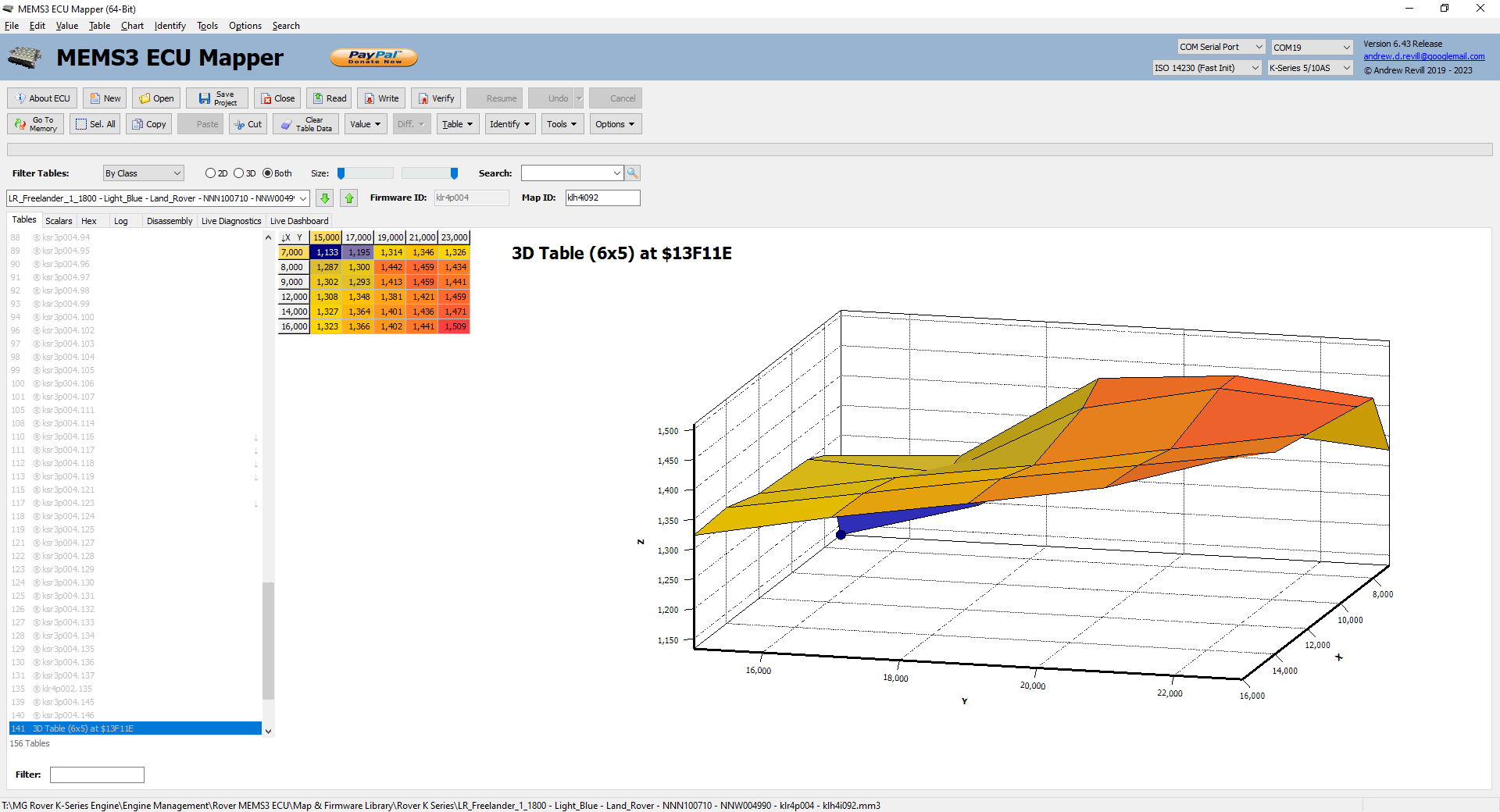
Initially that seemed to make no sense at
all, as one was a 2D table and one was a 3D table. The 2D table appears in
nearly all of the petrol MEMS3 firmwares and gives the injector flow rate as a
function of battery voltage (note this is not related to the “dead time” caused
by the difference in opening and closing delays on the injector as this is
modelled separately, but models the actual flow rate during the time the
injector is open; it appears to make a small allowance for the fact that at
higher battery voltages the pump will work harder pushing more fuel through the
regulator, and there is inevitably some degree of “softness” or natural
impedance to the regulator, therefore the fuel pressure will rise slightly with
increasing battery voltage). The 2D table does not appear in Land Rover
Freelander ECUs. The 3D table only appears in Land Rover Freelander ECUs. This
would only make sense if the second axis was fuel pressure, but this would
require the Freelander engine to have a fuel pressure sensor which is not
present on any other K Series engine I’ve seen. A bit of Googling turned up
this: https://www.autodoc.co.uk/car-parts/sensor-fuel-pressure-12909/land-rover/freelander/freelander-ln/15591-1-8-16v-4x4
- a Freelander 1.8K Fuel Pressure Sensor! So the
automated algorithms was right and I was wrong. This was indeed the equivalent
table in a Freelander ECU, which I would never have spotted just looking at the
data. Looking at the code, there’s just one extra line around the injector flow
rate lookup where the ECU loads the fuel pressure variable into register d3.
The proximity-scoring algorithm had recognised the identical code either side
and scored it highly enough to count as a clear match. The code-alignment
algorithm had extracted the runs of identical code before and after, then in
the final sorting stage had put them back together again, leaving identical
code listings with the one single additional instruction ending up on the
“uncorrelated” list.
To take into account the few places where
I had put things together by eye where the automated algorithm had missed them,
I manually realigned the two petrol table files to produce this: Tables.RoverKSeries.Override.xlsx.
The final piece of the jigsaw was to add
code which would automatically update the definition files used by MEMS Mapper
with all of table and scalar information generated above. This is now done and
included in the in the latest builds available for download.
And The Result Is …
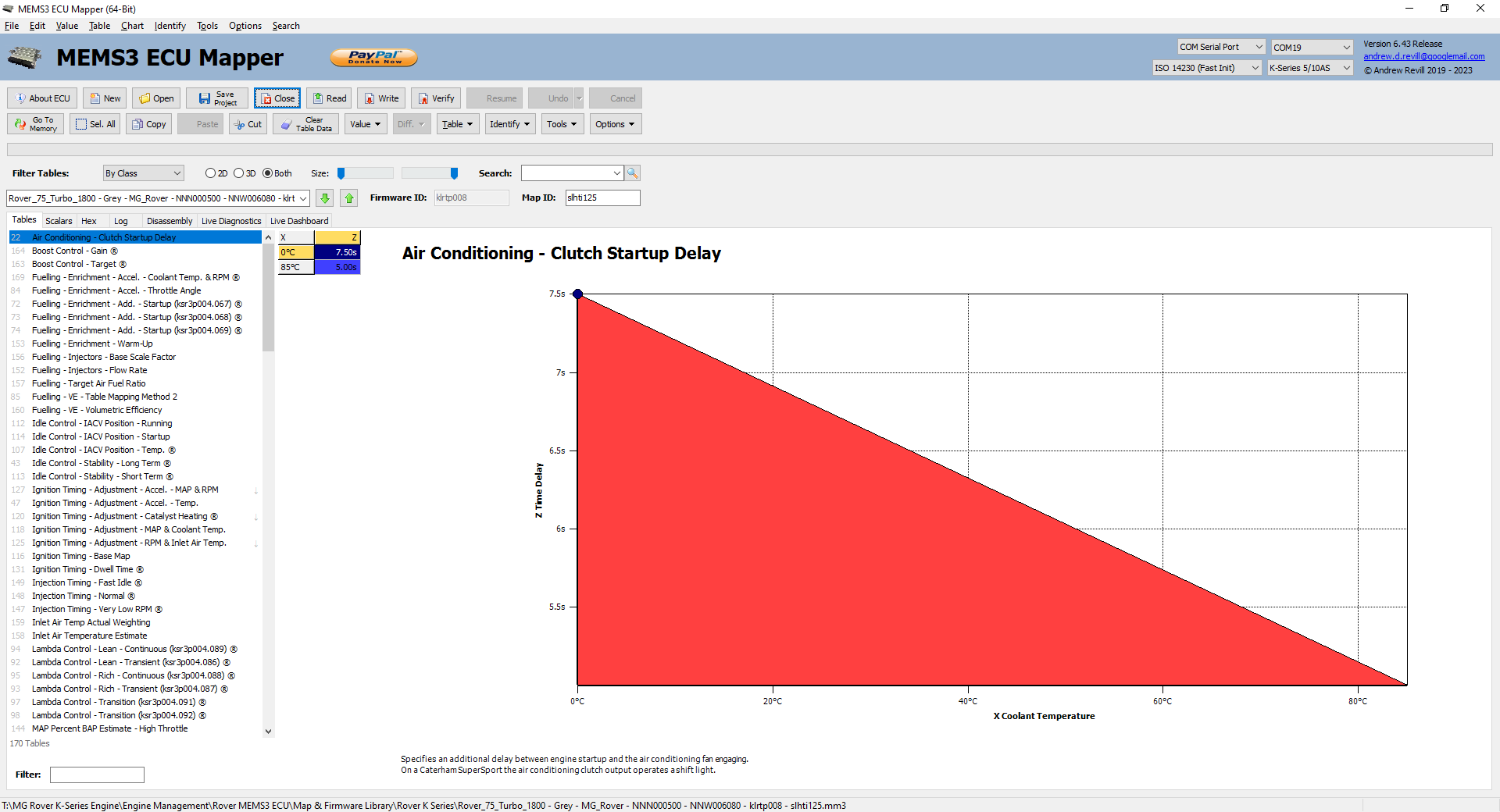
Every table and every scalar I’ve ever been able to identify in any firmware version (mostly in the
ksr3p004 VVC firmware as that’s what I’ve focused on during research) now
appears correctly defined in files for all other firmware version which use it
(in this case a Rover 75 ECU). And because I’ve classified all of the matching
tables and scalars, even where I don’t know what they do yet, any tables and
scalars that I identify in any firmware version in the future will also appear
in files for all other firmwares which use them. Every single table and nearly
every single scalar in every firmware is now assigned to a class definition.
The only exceptions are those that are only used in one single firmware
version, and the few scalars which are not directly references in code (there
are mostly references as pointers in tables of data records, and are not
therefore susceptible to this technique). In theory, this should mean that the
in-application data-based matching algorithm should not need to be used in
future.
It’s a big step forward in terms of
consistently analysing and classifying the data definition used by all of the
different MEMS3 firmware versions.
Now back to the engine simulator and
disassembler to try to identify more features. Oh yeah … I haven’t written up
my full engine simulator yet, have I? There’s another project to document when
I can find the time!